Adacor realisiert Deep-Learning-Projekte zur vorausschauenden Analyse bezüglich der Serverstabilität oder der Entwicklung fortschrittlicher Datenbanksysteme sowie zur Verbesserung der Netzwerkarchitekturen. Darüber hinaus berät und unterstützen wir als Managed Cloud Solution Provider Kundenunternehmen, die Vorhaben im Deep Learning realisieren möchten.
Was ist Deep Learning?
Deep Learning ist ein Teilbereich des maschinellen Lernens. Mit der Methode lassen sich Muster in Daten erkennen. Zahlreiche Anwendungen im Alltag basieren auf Deep Learning. Dazu zählen Softwareanwendungen zur Gesichtserkennung für die Identifikation von Personen, Bilderkennungsverfahren, die bei der Entwicklung selbstfahrender Autos zum Einsatz kommen, oder bestimmte für die Genanalyse bedeutende Algorithmen. Aktuell ist das Werkzeug der bestmögliche existierende Datenanalyseansatz. Um die Potenziale von Deep Learning auszuschöpfen, wandeln Data Scientists große Datenbestände in maschinenlesbare Formate um. Ziel ist, für das Deep Learning „Trainingsmethoden“ zu etablieren, die „Erlerntes“ immer wieder mit neuen Inhalten abgleichen, verknüpfen und vergleichen. Daraus resultierend gelingt es den Algorithmen, Prognosen oder „Entscheidungen“ zu treffen, die wiederum neue Muster und Modelle hervorrufen.
So setzt Adacor Deep Learning ein
In Hinblick auf Deep Learning ist Adacor für Unternehmen in zweierlei Hinsicht ein guter Partner. Zum einen etablieren wir eigene Deep-Learning-Projekte zur vorausschauenden Analyse hinsichtlich der Stabilität von Servern, zur Entwicklung fortschrittlicher Datenbanksysteme sowie zur Verbesserung von Netzwerkarchitekturen. Wir Data Scientists bei Adacor verfügen über weitreichende Erfahrungen und Know-how im Deep Learning und bei den dazugehörigen mathematischen Konstrukten. Dieses Wissen geben wir weiter und beraten Unternehmen, die auf ihren eigenen Systemen Deep-Learning-Vorhaben umsetzen wollen. Zusätzlich unterstützen wir bei der technischen Konzeption und zeigen erfolgreiche Transitionswege auf.
Die Umsetzung von Deep-Learning-Projekten ist kompliziert, da sie enorme Rechenleistungen erfordern. Das Training eines Deep-Learning-Modells kann Stunden, Tage oder Wochen dauern, abhängig von der Größe der Daten und der verfügbaren Rechenleistung. Kaum übertroffene Performance liefern in diesem Bereich Grafikprozessoren (GPU). Als Beispiel sind die extrem leistungsfähigen Pay-per-use-Dienste wie die Tensor Processing Unit (TPU) von Google zu nennen. Gebühren fallen für die Nutzung von Cloud TPU mit dem von Google entwickelten Hochgeschwindigkeitsnetzwerk an, das zum Trainieren von Machine-Learning-Modellen genutzt wird. Die Projekte laufen ausschließlich in der Google Cloud. Adacor unterstützt Unternehmen bei entsprechenden Projekten bei der Konzeption, der Transition und dem Betrieb.

Adacor Cloud Adoption Framework
Mit dem Cloud Adoption Framework brechen wir IT-Projekte in überschaubare Arbeitspakete auf.
Mehr als 50 Tools, Vorlagen und geführte Workshops
In 5 Min verschafft Ihnen Adacor CEO Andreas Bachmann mit seinem Video einen Überblick
Hintergründe zu Deep Learning
Oft wird Deep Learning mit künstlicher Intelligenz (KI) gleichgesetzt. Das ist nicht korrekt. Der Teilbereich des Machine Learnings unterscheidet sich von anderen Methoden des maschinellen Lernens darin, dass der Mensch weder in die Datenanalyse noch in den Entscheidungsprozess eingreift. Ihm obliegt die Aufgabe, die Informationen für den Lernprozess bereitzustellen und die Prozesse zu dokumentieren. Die Analyse, das Prognostizieren und das Fällen von Entscheidungen übernimmt der Algorithmus. Deep Learning hat einen beispiellosen Grad an Genauigkeit erreicht.
Was sind neuronale Netze?
Normalerweise wird die Methode in Anlehnung an eine neuronale Netzwerkarchitektur implementiert. Spricht man in der IT von „neuronalen Netzen“ ist nicht die Nachbildung des menschlichen Gehirns oder Nervensystems gemeint. Diese Analogie stammt aus den „Kinderschuhen“ der künstlichen Intelligenz. Es geht vielmehr um hochgradige Abstraktionen. Sie dienen dazu, Modelle für die Informationsverarbeitung von großen Datenmengen (Big Data) zu bilden.
Neuronale Netze bestehen aus mehreren Neuronen, die als Units oder Einheiten bezeichnet werden. Sie übernehmen die Aufgabe, Informationen aus der Umwelt oder von anderen Neuronen aufzunehmen und an andere Units oder die Umwelt in modifizierter Form weiterzuleiten.
Es gibt drei unterschiedliche Arten von Neuronen:
1. Die „Input-Units“ erhalten von der Außenwelt Signale (Reize, Muster).
2. Die „Output-Units“ geben Signale an die Außenwelt weiter.
3. Die „hidden Units“ befinden sich zwischen Input- und Output-Units und repräsentieren die Außenwelt.
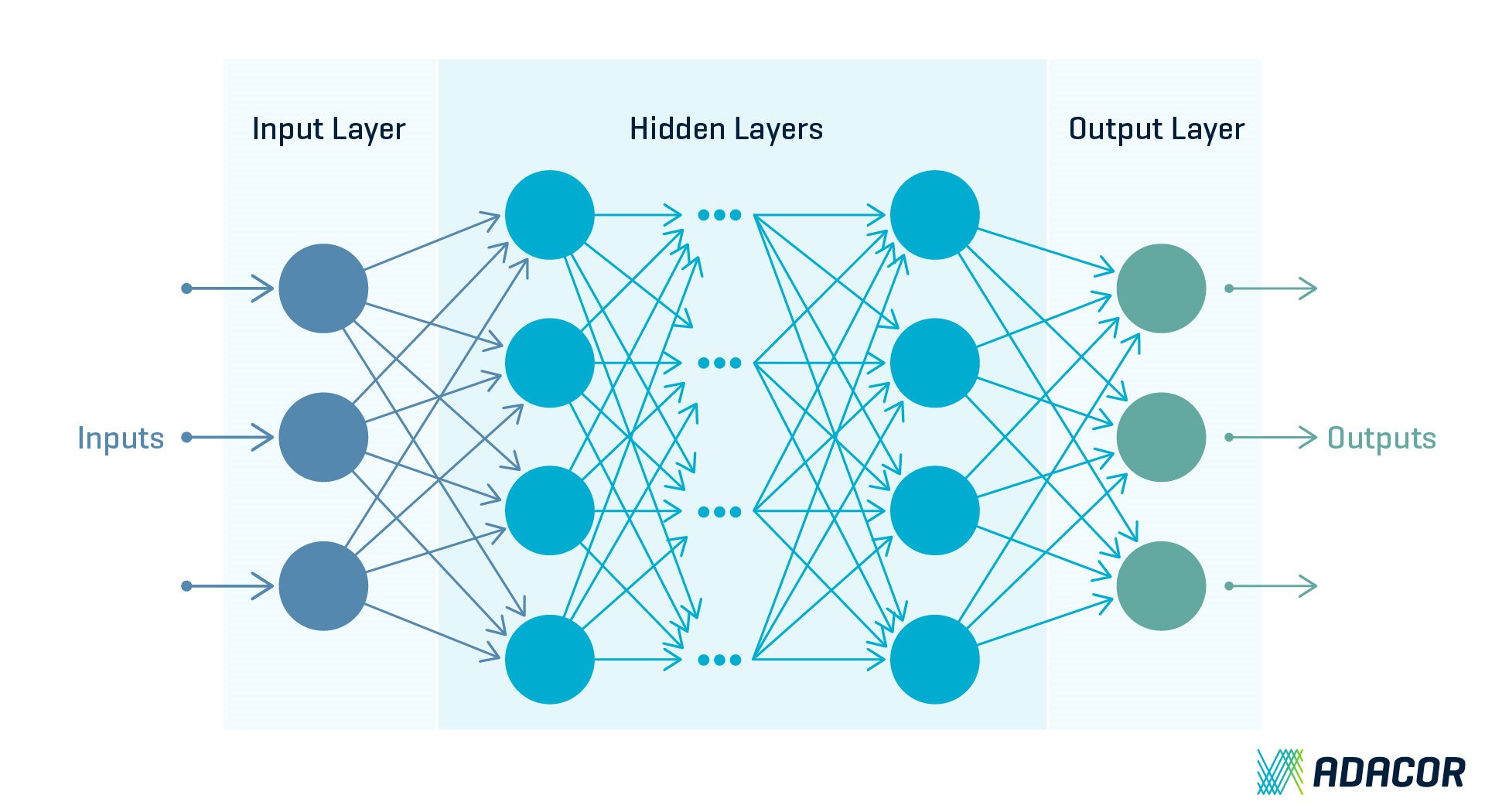
Deep-Learning-Modell
Umso mehr Neuronen und Schichten es gibt, desto komplexere Sachverhalte lassen sich in dem System abbilden. Ein tiefes neuronales Netzwerk – wie es das Deep Learning benötigt – kombiniert mehrere nicht lineare Verarbeitungsschichten. Eingabeebene, Ausgabeebene und „ausgeblendete“ (hidden) Ebenen sind über Knoten miteinander verbunden. Die Tiefschichtigkeit entsteht, indem jede ausgeblendete Ebene die Ausgabe der vorherigen Ebene als Eingabe verwendet. Der Begriff „tief“ bezieht sich auf die Anzahl der Schichten im Netzwerk – je mehr Schichten, desto tiefer das Netzwerk. Herkömmliche neuronale Netze enthalten zwei oder drei Schichten, während Netzwerkstrukturen des Deep Learnings Hunderte von Schichten enthalten können.
Die Bilderkennung – ein anschauliches Beispiel
Anhand der Bilderkennung lässt sich die Methodik anschaulich erklären. Angenommen, es gibt eine Reihe von Bildern. In diesen enthält jedes Bild eine von vier verschiedenen Objektkategorien. Soll das Deep-Learning-Netzwerk automatisch erkennen, welches Objekt sich in jedem Bild befindet, wird das Netzwerk mit einer bestimmten Anzahl von Trainingsdaten gefüttert. Anhand derer beginnt das Netzwerk die spezifischen Objektmerkmale zu verstehen und sie der entsprechenden Kategorie zuzuordnen. Jede Schicht im Netzwerk nimmt Daten von der vorherigen Schicht auf, transformiert sie und leitet sie weiter. Nach einer Weile wird das Netzwerk nicht nur die im Trainingslauf erlernten Merkmale als Ordnungssystem nutzen, sondern die Komplexität und Detailliertheit des Lernens von Schicht zu Schicht erhöhen. Es lernt unmittelbar aus den Daten, ohne jeglichen Einfluss auf die einzelnen Funktionen.
Voraussetzungen für Deep-Learning-Projekte
Zur Etablierung von Deep Learning ist ein sorgfältiges Pre-Processing notwendig. Ein digitalisierter normierter Datenbestand kann die Basis für Deep Learning bilden – oder andersherum ausgedrückt: Die Ergebnisse des Deep Learnings sind nur so gut wie die Qualität der Daten. Ausgefeilte Algorithmen gleichen eine schlechte Datenbasis nicht aus. Das Pre-Processing benötigt qualifiziertes Personal. Bei Adacor arbeiten Data Scientists und Entwickler Hand in Hand. Vom Importieren und Bereinigen der Daten bis zum Anpassen des maschinellen Lernmodells gilt es, Daten zu standardisieren und die Modellanpassung kontinuierlich zu verbessern.
Welche Anwendungsszenarien bietet Deep Learning?
Viele Branchen profitieren von der Methode, wie die folgenden Beispiele zeigen.
- Die Automobilindustrie arbeitet an der Entwicklung selbstfahrender Fahrzeuge. Wird ein Auto automatisch langsamer, wenn es sich einem Fußgängerüberweg nähert, stecken dahinter Bilderkennungsprogramme, die auf Deep-Learning-Methoden beruhen.
- Weist ein Geldautomat eine gefälschte Banknote zurück, ist dies das Ergebnis neuer Bilderkennungsverfahren. Sie arbeiten weitaus präziser, als es die Sinne eines Menschen tun könnten.
- Wenn wir im Ausland mit dem Smartphone Schilder fotografieren und uns das Gerät die richtige Übersetzung vorliest, basiert das Ergebnis auf weiter entwickelter Deep-Learning-Methoden.
- Auf Deep Learning basierende Algorithmen werden in der Genanalyse eingesetzt. Der Grund ist, dass sie rasend schnell in Milliarden von Datensätzen Auffälligkeiten identifizieren können, die auf Gendefekte oder Krankheiten hindeuten. Der zeitliche Aufwand für solche Analysen konnte in den letzten Jahren von Wochen auf Minuten reduziert werden.
- Deep Learning wird außerdem zur Personen-Identifikation durch Gesichtserkennung, zur Textübersetzung und Spracherkennung sowie für fortschrittliche Fahrerassistenz-Systeme eingesetzt.
Fazit: Ist Deep Learning die Zauberformel für die Zukunft?
Deep Learning ist ein statistisches, kein logisches Modell. Die Angst ist unberechtigt, dass intelligente Maschinen der Menschheit bald überlegen sein könnten. Zwar sind Maschinen in vielen Bereichen besser oder genauer als Menschen, auf den „Zufall“ können sie nicht mit „sinnvollen“ Handlungen oder Entscheidungen reagieren. Es gibt nicht für jedes Problem in der Informationstechnologie ein Modell, das als „Trainingscamp“ für Deep Learning dienen kann. Tatsächlich ist das menschliche Gehirn viel leistungsfähiger als jede Maschine und verbraucht deutlich weniger Energie. Wenn wir aufhören, maschinelle mit menschlicher Intelligenz zu vergleichen, dann werden wir feststellen, dass Mensch und Maschine im Alltag ein leistungsstarkes Team bilden können.
Deep Learning ist ein Subtyp des maschinellen Lernens und eine hervorragende Methodik, um Probleme in Projektprozessen oder bei der Informationsverarbeitung zu untersuchen und zu analysieren. Adacor konnte mit dieser Methodik für zahlreiche Subprobleme Algorithmen entwickeln, die der Verbesserung der Servicequalität sowie der Leistungsfähigkeit der Server dienen.
Sie möchten mehr Informationen zu KI- und Predictive-Themen?
Dann haben wir weitere spannende Artikel im Blog für Sie zum Lesen. Unsere Data Scientists Simon Krannig und Charaf Ouladali erklären, wie Unternehmen von Predictive Analytics profitieren, wie sich Maschinelles Lernen realisieren lässt und was genau hinter dem Begriff Supervised Learning steckt. Zudem erfahren Sie von unserem Product Manager Valentin Rothenberg, wie Adacor im Rahmen eines innovativen KI-Projekts Predictive Monitoring einsetzt.