Die beeindruckenden Fortschritte bei sprachbasierten KI-Diensten wie OpenAI’s ChatGPT, Microsoft Bing Chat und Google Bard haben zu einer breiten Akzeptanz von KI-Technologie geführt. Diese Entwicklungen haben das Interesse von Unternehmen geweckt und zahlreiche Ideen hervorgebracht, wie KI-Modelle genutzt werden könnten, um die betriebliche Effizienz und das Kundenerlebnis zu verbessern.
Diese Möglichkeiten sind jedoch mit einer großen Herausforderung verbunden: Wie können Unternehmen generative KI bzw. GenAI nutzen, ohne sensible Daten und interne Dokumente mit externen Diensten teilen zu müssen?

KI-Sprachmodelle verstehen
KI-Sprachmodelle, auch als Large Language Models (LLMs) bekannt, sind darauf ausgelegt, von einer unglaublich großen Menge an Text-Daten zu lernen. Führende KI-Dienste wie OpenAI’s ChatGPT oder Google Bard speisen ihre Modelle mit so gigantischen Datenmengen, dass deren Umfang mit dem des gesamten frei zugänglichen Internets vergleichbar ist. Die zur Verarbeitung dieser immensen Datenmenge erforderliche Rechenleistung ist beeindruckend. Für den Trainingsprozess werden Hunderte oder sogar Tausende von Grafikprozessoreinheiten (GPUs) eingesetzt, die dazu mehrere Wochen oder gar Monate in dauerhaftem Betrieb sind. Dies macht das Training dieser Modelle zu einem der aufwendigsten Unterfangen im Bereich der KI. Aber was lernen diese Modelle während dem Training eigentlich?
Bei textgenerierenden LLMs ist das zugrunde liegende Prinzip elegant einfach. Basierend auf Milliarden von Beispielen haben diese Modelle die Aufgabe, die wahrscheinlichste Fortsetzung für einen gegebenen Text auszugeben. Wenn zum Beispiel der Text „Paris ist die Hauptstadt …“ in das Modell eingespeist wird, würde es aufgrund seines Trainings ausgeben, dass die wahrscheinlichste Fortsetzung „Paris ist die Hauptstadt von Frankreich“ lautet. Eine andere denkbare Fortsetzung ist „Paris ist die Hauptstadt der Mode“. Welche dieser Antworten nun ausgegeben wird, entscheidet das Modell basierend auf möglicherweise existierendem Kontext.
Diese Funktionsweise ist den meisten von uns nicht unbekannt, da sie exakt der Autocomplete-Funktion auf unseren Smartphones entspricht. Tatsächlich wird diese Funktion bei modernen Smartphones bereits von LLMs ausgeführt.
Ist das initiale Training abgeschlossen, so hat das Modell gelernt, welche Wörter in welchem Kontext am wahrscheinlichsten zusammen auftreten. Daraufhin folgen zusätzliche Trainingseinheiten auf speziellen Daten, die in Dialogform, Frage-Antwort Paaren etc. vorliegen. Somit wird das Modell geschickt darin, eine Benutzeranfrage fortzusetzen, als wäre es ein menschlicher Gesprächspartner. Danach sorgen umfangreiches Experten-Feedback und Feinabstimmungen dafür, dass das Modell Antworten liefert,die korrekt und benutzerfreundlich sind.
Diese Konfiguration verleiht LLMs die überraschende Fähigkeit, eine Vielzahl von Anweisungen auszuführen – vom Bereitstellen von Programmierberatung bis zum Vereinfachen komplexer Sachverhalte und vielen weiteren Themen. Dies liegt daran, dass das LLM gelernt hat, ein kompetentes und hilfsbereites Gegenüber zu simulieren.
Verknüpfen Sie Ihre Daten mit KI-Sprachmodellen
Trotz dieser spannenden Fähigkeiten gibt es einen großen Nachteil bei diesen Modellen: Sie können Antworten nur auf Grundlage von Informationen generieren, welche auch in den Trainings-Daten vorhanden sind. Diese Einschränkung schließt zwei besonders kritische Informationsquellen aus.
- Erstens kennt das Modell keine aktuellen Ereignisse, Nachrichten, Entdeckungen oder Diskussionen, die nach Abschluss des Modell-Trainings stattgefunden haben.
- Zweitens bleiben nicht-öffentliche Daten wie interne Geschäftsdokumente für das Modell unzugänglich.
Infolgedessen wird das Modell nicht in der Lage sein, spezifische Fragen zu Ihrem Geschäftsbetrieb zu beantworten.
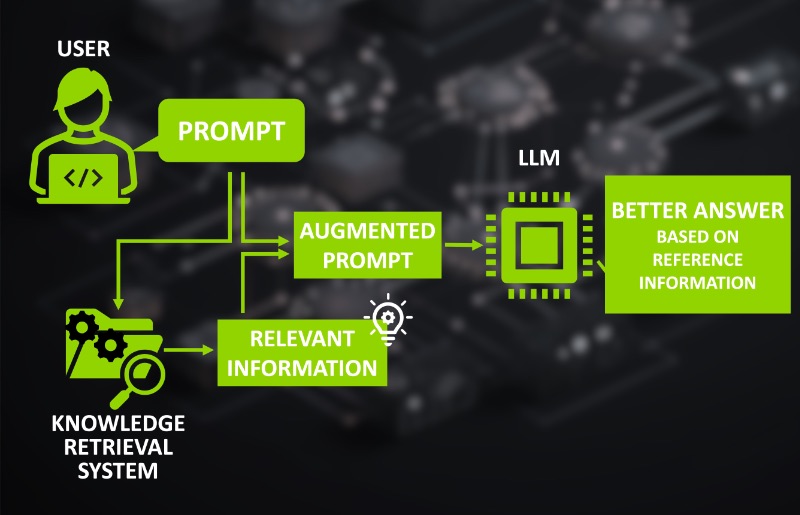
Sind wir dann mit LLMs gefangen, die nur an der Oberfläche der für uns relevantesten Informationen kratzen können? Glücklicherweise lautet die Antwort „nein“. Die Lösung ist zunächst denkbar einfach: Stellen wir dem Modell eine Frage zu einem Thema, welches nicht in den Trainingsdaten enthalten ist, fügen wir in einem weiteren Absatz auch die entsprechenden Referenzinformationen hinzu. Dabei kann es sich um einen Zeitungsartikel oder den Inhalt eines privaten Dokuments handeln. Solange die relevanten Informationen enthalten sind, wird das LLM dies berücksichtigen und es zur Beantwortung unserer Fragen verwenden.
Dieser Prozess würde erfordern, im Voraus über die relevanten Referenzinformationen Bescheid zu wissen und diese schnell verfügbar zu haben. Dies kann durch ein automatisiertes „Knowledge Retrieval System“ erledigt werden. Ein solches System agiert zwischen dem Nutzer und dem LLM. Es funktioniert zunächst wie eine Suchmaschine auf unseren individuellen Dokumenten und ermöglicht es PDFs, Protokolle, Quellcode und andere textbasierte Dokumente zu finden und nach ihrer Relevanz für die Nutzerfrage zu sortieren. Dann ergänzt es die ursprüngliche Anfrage um Absätze mit den relevantesten Abschnitten aus den gefundenen Texten. Diese erweiterte Anfrage wird dann anstelle der ursprünglichen an das LLM gesendet.
Solche Knowledge Retrieval Systeme können auf vielfältige Weise umgesetzt werden. Wenn es jedoch um unser Anwendungsbeispiel geht, stehen semantische Suchmaschinen im Mittelpunkt. Sie basieren selbst auf einer Variante von KI-Sprachmodellen, sogenannten „Embedding-LLMs“, welche speziell dafür trainiert wurden, die Semantik eines gegebenen Textes numerisch zu kodieren. Die so gewonnenen semantischen Information aus jedem Textstück in unseren Dokumenten wird anschließend in einer Vektordatenbank gespeichert. Dieses Zusammenspiel zwischen „Embedding-LLMs“, Vektordatenbanken und semantischen Suchmaschinen ist eine enorm mächtige Erweiterung für die Verwendung von KI-Sprachmodellen.
Generative KI: Einführung in die Funktionsweise
Erfahren Sie im Video, wie sich Large Language Models mit eigenen Datenquellen verbinden lassen, um Ihrem Unternehmen intelligente Analysen und präzise Antworten aus Ihren eigenen Datenbeständen zu ermöglichen. Es ist verhältnismäßig unaufwendig eine eigene generative KI selber zu hosten.
Generative KI: Open-Source Sprachmodelle als Alternative
Während die Idee sehr attraktiv ist, eine benutzerdefinierte Suchmaschine zusammen mit einem LLM zu verwenden, wirft sie einen erheblichen Vorbehalt auf: Jedes Mal, wenn wir dieses Setup verwenden, übermitteln wir möglicherweise eine große Menge an privaten oder schützenswerten Daten an das Unternehmen, welches das Modell oder den KI-Dienst besitzt und betreibt. Bedenken Sie, dass jede einzelne Anfrage nun mit Daten aus Ihren eigenen Dokumenten ergänzt ist. Daher sollten alle Bedenken, die wir bezüglich Datenschutz und Datensicherheit gegenüber der Nutzung von großen KI-Diensten wie ChatGPT oder Google Bard ohnehin haben, nur noch akuter sein.
Die Lösung für dieses Dilemma mag zunächst unmöglich erscheinen: Wir könnten in Betracht ziehen, unser eigene generative KI zu hosten, um so die Kontrolle und das Eigentum am Modell zu übernehmen und sicherzustellen, dass die Datensicherheit jederzeit eingehalten werden und private Daten unsere Systeme nie verlassen. Doch ist es nicht so, dass das Training eines solchen Modells eine absurde Menge an Rohdaten, sehr umfangreiches und zeitaufwendiges menschlichem Feedback und unfassbare Mengen an Rechenleistung erfordert? Wie soll es also möglich sein, selbst die Kontrolle über ein LLM zu übernehmen?
Die Antwort liegt in der rasant wachsenden Open-Source-Community für LLMs, welche sich dem Training und der Entwicklung und Verbesserung von einsatzbereiten LLMs widmet. Somit liefern Open-Source LLMs das Versprechen des offenen Zugangs und ermöglichen es Einzelpersonen und Organisationen, KI-Sprachmodelle selbst zu betreiben und dabei die Kontrolle über ihre Daten zu behalten.
Einstieg in die KI mit Open-Source bietet zahlreiche Vorteile
Open-Source-Modelle sind im Vergleich zu ihren proprietären Gegenstücken tendenziell kleiner. Zum Vergleich: GPT-3 hat bereits beachtliche 175 Milliarden Modellparameter, während Google Bard und GPT-4 dies um den Faktor 3 bis 6 erhöhen. Die meisten Open-Source-Modelle fallen dagegen typischerweise in den Bereich von 3 Milliarden bis 40 Milliarden Parametern. Diese Größenunterschiede mindern zwar teilweise ihr Potenzial. Sie reduzieren jedoch vor allem den erforderlichen Rechenaufwand, um die Modelle zu betreiben.
Die Open-Source-Landschaft lässt sich ungefähr in zwei Gruppen einteilen. Die erste Gruppe konzentriert sich auf die sorgfältige Entwicklung von grundlegenden LLMs wie Pythia von EleutherAI, MPT von MosaicML und das Falcon-Modell vom Technology Innovation Institute. Diese sind in der Regel Textfortsetzungsmodelle, die noch nicht auf konversationelle Daten abgestimmt sind. Deren Training verbraucht jedoch den mit Abstand größten Teil der Rechenressourcen im gesamten Lebenszyklus des Trainings einer generativen KI.
Die zweite Gruppe übernimmt dann diese Grundmodelle und optimiert sie für verschiedene Aufgaben, einschließlich des Konversations-Textgenerationsstils, welcher für Chat-Bots und KI-Assistenten verwendet wird. Das Ergebnis ist eine Vielzahl von einsatzbereiten Modellen, die für verschiedene Anwendungsfälle optimiert sind. Viele dieser Modelle sind für den kommerziellen Gebrauch lizensiert. Vor allem können sie von Einzelpersonen und Unternehmenen selbst gehostet werden.

Moderne Datenplattformen & Generative KI
Wir sind der richtige Partner für jedes Szenario
- Generative KI
- Machine Learning
- Datenplattform auf Azure
- Datenplattform in Private Cloud
Die sichere Verknüpfung mit den unternehmenseigenen Daten gelingt durch die Anbindung an Knowledge Retrieval Systeme. Genau dies führt dazu, dass selbst kleinere Modelle durch ihren geringeren Rechenaufwand ein beachtliches Potenzial bieten. Drittanbieter müssen für die meisten Anwendungen nicht mehr genutzt werden.
Die Rechenanforderungen für die meisten Open-Source-Modelle sind bemerkenswert bescheiden – eine Cloud-Virtual-Machine, ausgestattet mit einer einzelnen High-End-GPU, ist in der Regel ausreichend, um eine generative KI zu hosten und für den internen Gebrauch zur Verfügung zu stellen.
Diese niedrige technische Anforderungen ermöglichen es, selbst kleinen Unternehmen und Start-ups das Potenzial moderner KI-Sprachmodelle zu nutzen.
Befürchtungen hinsichtlich des Datenschutzes können entkräftet werden: Open Source-LLMs stellen somit eine Alternative für alle Unternehmen dar, die ihre Daten nicht mit den großen KI-Dienstleistern teilen dürfen.