Auf Basis günstiger Rechenleistung und großer Datenmengen hat sich die Künstliche Intelligenz in den vergangenen Jahren immens weiterentwickelt: von einer reinen Wissenschaft der Computer-Programmierung hin zu einem breit aufgestellten Forschungsbereich, der unter anderem die Neurologie und Psychologie einbezieht. Darüber hinaus ist das Thema für Unternehmen spannend. Adacor setzt zum Beispiel zunehmend auf intelligente Systeme, momentan im Teilbereich „Maschinelles Lernen“.
Intelligente Systeme dank künstlicher Intelligenz
Künstliche Intelligenz (KI) oder englisch Artificial Intelligence (AI), ist zu einem wesentlichen Thema für Wissenschaftler und Unternehmen geworden. Der Begriff beschreibt zahlreiche Technologien zum Erbringen intelligenter Leistungen, die ursprünglich dem Menschen vorbehalten waren. Autonomes Fahren zählt genauso dazu wie Roboter, Spracherkennung oder Tools zur Datenanalyse.
Laut der im vergangenen Jahr veröffentlichten Studie „Machine Learning im Unternehmenseinsatz“ von Crisp Research beschäftigen sich bereits 64 Prozent von gut 250 befragten IT-Entscheidern aus dem deutschsprachigen Wirtschaftsraum mit KI-Techniken. Die McKinsey-Studie „Smartening up with Artificial Intelligence (AI) – What’s in it for Germany and its Industrial Sector?“ sieht in KI einen Wachstumsmotor mit dem Potenzial, das Bruttoinlandsprodukt von Deutschland bis 2030 um bis zu vier Prozent oder 160 Milliarden Euro steigen zu lassen. Gleichzeitig gehen mit der Entwicklung Risiken einher. So warnten im Februar 2018 führende Experten aus Forschung und Entwicklung vor den Gefahren von KI, die durch bösartige und destruktive Nutzung entstehen. Sie wiesen darauf hin, dass die Entwicklung der KI an einem Punkt sei, an dem ein gemeinsames Eingreifen noch möglich ist. Politik, Forschung und Wirtschaft seien aufgefordert zusammenzuarbeiten. Als Beispiele führten sie die bei der Garmischer NATO-Konferenz von 1968 festgelegten und immer noch geltenden Grundlagen zur Softwareentwicklung an sowie das 1975 ausgerufene Moratorium der biologischen Forschung. Es dient immer noch als Grundlage für neue Selbstbeschränkungen in der Genforschung.
Maschinelle Lernen ist kein Selbstläufer – Maschinen brauchen Beispiele zum Lernen
Unter KI werden verschiedene Teilbereiche zusammengefasst. Einer ist das „Maschinelle Lernen“ beziehungsweise „Machine Learning“ (ML). Es beschreibt mathematische Techniken (Algorithmen), die einem intelligenten System – oft als „Maschine“ bezeichnet – ermöglichen, aus „Erfahrungen“ selbstständig „Wissen“ zu generieren. Und das in der Regel in einem Bruchteil der Zeit, die ein Mensch dafür brauchen würde.
Grundlage für Machine Learning sind Daten. Diese liegen aufgrund des technologischen Fortschritts heute in großer Anzahl und Bandbreite vor. In Form von Zahlen oder Bildern dienen sie künstlichen Systemen als Beispiele zum Lernen. Anschließend kann das intelligente System das Gelernte auf unbekannte Daten anwenden: Es erkennt in den vorher erlernten Strukturen Gesetzmäßigkeiten und kann dadurch auch unbekannte Daten bewerten (Lerntransfer).
Maschinelles Lernen wird im Wesentlichen in zwei Kategorien eingeteilt: Supervised und Unsupervised Learning. Beim „Supervised Learning“ oder „überwachten Lernen“ wird ein intelligentes System befähigt, bekannte Muster in unbekannten Daten zu erkennen und die Daten entsprechend vorgegebener Ergebniskategorien zu klassifizieren. Dafür werden in einem ersten Schritt Daten, zum Beispiel Bilder von Katzen und Hunden, in einen vorher entwickelten Algorithmus eingelesen. Der Algorithmus „lernt“ zunächst, indem er die Daten anhand verschiedener Merkmale (Attribute) analysiert. Die Ergebniskategorien (im Beispiel: Katze und Hund) sind dabei vorgegeben. Anschließend ist der Algorithmus in der Lage, neue Daten entsprechend der Ergebniskategorien zu klassifizieren: Das System „erkennt“ zum Beispiel Bilder von Hunden oder Katzen. Beim „Unsupervised Learning“ oder „unüberwachten Lernen“ erhält das intelligente System im Gegensatz dazu die Daten ohne die Ergebnisinformation. Ziel ist es, in den Daten „unbekannte Muster“ zu finden. Das heißt, das System schließt von sich aus auf Strukturen und Ergebnisse.
Das versteht man unter Supervised Learning
- Einlesen und Zuordnen der Daten zu den verschiedenen Attributen
- Transformieren der Daten: Nicht-numerische Werte werden in Zahlen (= numerische Werte) umgewandelt.
- Explorative Datenanalyse (EDA): Die eingelesenen Daten werden auf Plausibilität geprüft. Gegebenenfalls werden sie bereinigt oder ersetzt.
- Einstellen der Settings: Es wird festgelegt, wofür der Algorithmus eingesetzt wird: zum Prognostizieren (zum Beispiel die Wahrscheinlichkeit, an einer Krankheit zu erkranken) oder zum Klassifizieren (zum Beispiel von Bildern).
- Durchsuchen der Daten mit dem Algorithmus: Das System durchsucht die Daten und lernt.
- Ergebnis und Dokumentation: Das System gibt das Ergebnis aus (Output) sowie eine Dokumentation der Auswertungen. Sichtbar ist, wie sich der Algorithmus beim Durchsuchen der Daten jeweils entschieden hat.
- Evaluierung: In einem abschließenden Schritt wird geprüft, ob die Ergebnisse stimmen können.
Supervised Learning stützt sich auf verschiedene Algorithmen
- Clustering: Der Algorithmus fasst ähnliche Daten zu Gruppen zusammen. Dafür werden die als Zahlenwerte vorliegenden Daten als „ähnlich zueinander“ bewertet, wenn deren Abstände zueinander gering sind. Liegen alle Daten so dicht beieinander, dass verschiedene Gruppen nicht erkennbar sind, funktioniert das Clustering nicht.
- Decision tree/Entscheidungsbaum: Der Algorithmus durchsucht die Daten anhand bestimmter hierarchisch aufeinanderfolgender Entscheidungsregeln. Grafisch dargestellt, entsteht durch die verschiedenen Verzweigungen, an denen der Algorithmus Entscheidungen trifft, das Bild von einem Baum.
- Künstliche neuronale Netze: Der Algorithmus arbeitet entsprechend einem Modell, das auf dem menschlichen Gehirn und neuronalen Prozessen basiert. Das bedeutet: Der Algorithmus funktioniert über miteinander verbundene Knotenpunkte (Neuronen, grafisch meist als Kreise dargestellt).
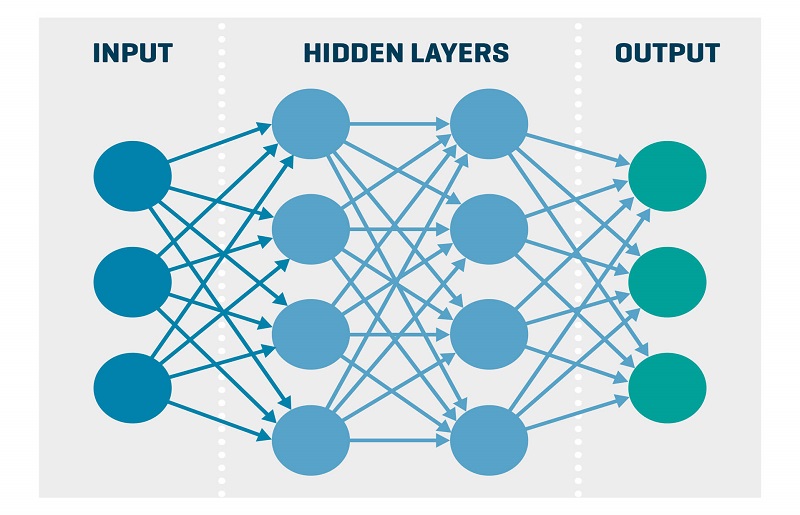
Künstliche neuronale Netzte
Beim Analysieren der Daten werden verschiedene Knotenpunkte aktiviert, die über die Verbindungen wiederum andere Knotenpunkte aktivieren. Diese sogenannten „hidden layers“ stehen für verschiedene Attribute. Bei der Analyse wird lediglich festgelegt, wie viele Knotenpunkte – und damit Merkmale – der Algorithmus in seine Bewertung einbezieht. Es wird nicht aktiv festgelegt, welche Attribute einbezogen werden.
- Random forest: Das Klassifikationsverfahren besteht aus mehreren unkorrelierten – sprich nicht voneinander abhängigen – Entscheidungsbäumen. Sie alle sind unter einer bestimmten Art von Randomisierung (Zufallsverfahren) während des Lernprozesses gewachsen. Jeder „Baum“ trifft eine Entscheidung bezüglich der Klassifikation. Letztendlich bestimmt die am häufigsten gewählte Klassifikation über das endgültige Ergebnis.
Die verschiedenen Algorithmen werden bei einem Thema teilweise parallel angewendet und können mit unterschiedlicher Genauigkeit („Accuracy“) zu verschiedenen Ergebnissen kommen. Um die Genauigkeit eines Algorithmus zu überprüfen, wird lediglich ein bestimmter Anteil der Daten („Train-Data“) eingelesen. Mit diesen lernt das System. Anschließend wird mit den zurückbehaltenen Daten die Genauigkeit überprüft („Test-Data“): Dafür bekommt die Maschine die Kontrolldaten ohne Ergebnis. Das von ihr gelieferte Ergebnis wird anschließend mit dem tatsächlichen Ergebnis abgeglichen. Je nach Thema gilt ein Algorithmus in der Regel bereits als sehr gut, wenn die Genauigkeit zwischen 85 und 90 Prozent liegt.

Adacor Stellenmarkt
Lust die digitale Welt zu verbessern?
Bewirb dich jetzt!
Maschinenelles Lernen wird in Unternehmen angewendet
Günstige Rechenleistungen und große Datenmengen sind die Grundlage, auf der sich Machine Learning in den vergangenen Jahren immens weiterentwickeln konnte. Die Anwendungsgebiete sind vielfältig und lassen sich folgenden Schwerpunktbereichen zuordnen:
- Sachverhalte klassifizieren und Erkenntnisse aus vorhandenen Daten generieren: zum Beispiel verschiedenste Reports (Gewinn-Verlust-Darstellungen, Sales-Reports)
- Entwicklungen vorhersagen: Ein Beispiel ist die medizinische Diagnostik (zum Beispiel die Anfälligkeit für bestimmte Krankheiten).
Ein weiterer Bereich, in dem Machine Learning angewendet wird, sind sogenannte Social Bots und Chat Bots. Als spezielle Chat-Algorithmen filtern und klassifizieren sie Texte nach bestimmten Schlüsselwörtern und antworten dann entsprechend. Eingesetzt werden Chat Bots beispielsweise von Unternehmen in der Kundenbetreuung. Social Bots werden dagegen zum Beispiel in politischen Kampagnen eingesetzt. Auch sie durchsuchen das Netz nach bestimmten Keywords und posten dann in großer Anzahl entsprechende Kommentare. Ziel ist meist, eine beeinflussende Wirkung zu erzielen. Solche Bots werden von den Plattform-Betreibern gelöscht, sobald sie erkannt werden.
Machine Learning bei Adacor
Auch Adacor setzt zunehmend auf Machine Learning. Eine grundlegende Frage ist dabei, inwieweit das Generieren von Daten mit den Compliance-Richtlinien harmoniert. Nicht selten stellen die im Unternehmen geltenden Compliance-Regeln eine Grenze für die Anwendung von Machine Learning dar, denn die Compliance geht immer vor. Aktuell werden Machine Learning Tools in folgenden Bereichen eingesetzt:
Blog
Sogenannte Screenscraping- oder Crawling-Algorithmen durchsuchen diese Website (auf der sich gerade befinden) und klassifizieren bestimmte Informationen, wie beispielsweise spezifische in den Artikeln verwendete Begriffe. Das ermöglicht eine Analyse der Texte und deren anschließende Optimierung. In Verbindung mit Google Analytics kann zum Beispiel überprüft werden, welche Themen für die Leser besonders interessant sind.
Reports
Die in den verschiedenen Unternehmensbereichen vorliegenden Daten lassen sich mittels Algorithmen analysieren und miteinander in Beziehung setzen. Der Vorteil von Machine Learning liegt dabei in der Möglichkeit, eine große Menge an Daten schnell zu analysieren. Möglich sind unter anderem Auswertungen zu Verkäufen, Verlusten oder Gewinnen. So können relevante Faktoren identifiziert werden, die den Verkauf positiv oder negativ beeinflussen. Integriert in Dokumentationen, beispielsweise für den Vertrieb oder für Quartalsberichte, dienen die Ergebnisse als datenbasierte Grundlage für zukünftige Entscheidungen. Sind beispielsweise die Faktoren identifiziert, die Gewinne schwinden lassen, besteht die Möglichkeit, diese gegebenenfalls zu beeinflussen.
Prognosen
Ein weites Feld für Machine Learning bieten generell Prognosen. Ein Teilbereich ist das Predictive Monitoring, das im Gegensatz zum herkömmlichen Monitoring zukünftige Ausfälle prognostiziert. Adacor prüft beispielsweise aktuell, mit welcher Wahrscheinlichkeit sich Serverausfälle voraussagen lassen. Auch interne Mechanismen lassen sich mit ML-Tools erleichtern: Welche Aufgaben (Tasks) in den verschiedenen Unternehmensbereichen bieten einen Mehrwert? Welche Priorisierung ist sinnvoll? Ziel ist es, mit den Ergebnissen die Effizienz zu steigern oder Prozesse zu optimieren.
Fazit: Machine Learning bietet jede Menge Potenzial
Künstliche Intelligenz hat sich im Unternehmensumfeld zu einem festen Bestandteil mit Wachstumspotenzial entwickelt. Als Teilbereich von Künstlicher Intelligenz bietet Maschinelles Lernen Unternehmen jede Menge Möglichkeiten, das versteckte Potenzial ihrer Daten sinnvoll auszuschöpfen. Algorithmen generieren dabei „Wissen“ anhand von Beispielen und sind anschließend in der Lage, dieses Wissen auf unbekannte Daten anzuwenden. Supervised Learning wird vorzugsweise zum Klassifizieren von Daten und Vorhersagen von Entwicklungen eingesetzt. Adacor nutzt diese Möglichkeiten aktuell vor allem in internen Projekten wie im Blog (blog. adacor.com) sowie, um Daten in Reports besser aufzubereiten. Geplant ist, Machine Learning Tools zu nutzen, um Serverausfälle vorauszusagen sowie Kundenanfragen zu klassifizieren. Letztere können dann schneller den passenden Ansprechpartnern zugewiesen werden. Außerdem sollen das Wissen und die Kompetenz im Bereich Supervised Learning perspektivisch auch Kunden zur Verfügung gestellt werden.