Die Realisierung von Digitalisierungsprojekten stellt Managed Cloud Solution Provider wie Adacor vor neue Herausforderungen: Anwendungen, die skalierfähig, schnell bereitgestellt und sicher sein sollen, werden zunehmend in containerisierten Anwendungen mit Docker und Kubernetes umgesetzt. So werden komplexe Datensysteme mit relativ geringem Ressourcenverbrauch betrieben. Der niedrige Verbrauch basiert auf einer Technologie, die Container maschinenübergreifend verwaltet. Wenn ein Server ausfällt oder überlastet ist, startet Kubernetes den Container auf einer anderen Maschine neu. Dabei wird nicht derselbe Container auf einen anderen Rechner überspielt, sondern eine neue Kopie des Containers gestartet. Die Daten und Services, die ein beständiges Speichervolumen benötigen, können über einen Persistent Volume Claim verwaltet werden. Wie diese in Kubernetes Cluster eingebunden werden, erfahren Sie im folgenden Beitrag.
Container starten und „sterben” in regelmäßigen Abständen – nicht aufgrund technischer Fehler, sondern aus Gründen der Effizienz. Doch was passiert mit den Daten? Manche Services, zum Beispiel Datenbanken oder Mediendaten, benötigen Platz auf einem beständigen Speichervolumen – einem Persistent Volume. Daten, die erhalten werden sollen, können in Kubernetes-Clustern mit verschiedenen Methoden verwaltet werden.
Adacor Managed Kubernetes Cluster bieten maßgeschneiderte und skalierbare Plattformen für die jeweiligen Kundenanforderungen – je nach Bedarf in der Public Cloud von Azure oder auf einer Private-Cloud-Infrastruktur.
Speicherlösungen für Kubernetes finden auf Pod-Niveau statt. Sie sind an einen anwendungsspezifischen logischen Host gebunden, der verschiedene Anwendungscontainer enthält, die miteinander verbunden sind. Wird ein Pod mit einem Set von Storage Volumes konfiguriert, sorgt dies für Beständigkeit von zuvor definierten Daten. Die Container eines Pods teilen sich meistens den Storage, die Daten überleben dementsprechend Neustarts von Containern. Kubernetes bietet eine große Bandbreite von Volume-Arten an, darunter Azure Disk, CephFS, iSCSI oder vSphere Volume.

Managed Kubernetes
Nutzen Sie unsere gemangten Kubernetes-Services nach Ihrem individuellen Bedarf in der Adacor Private Cloud oder auf Microsoft Azure.
Informieren Sie sich jetzt über Adacor Managed Kubernetes!
Persistenter Speicher überlebt unabhängig von laufenden Instanzen
Ein persistenter Speicher ist so konzipiert, dass er unabhängig von einer laufenden Instanz überlebt. Daten, die wiederverwendet werden sollen, können über verschiedene Instanzen oder über die Lebensdauer einer bestimmten Instanz hinaus erhalten bleiben.
Wie sind die persistenten Speicher in den Kubernetes-Cluster eingebunden? Und widersprechen persistente Speicherlösungen nicht vollkommen der Art und Weise, wie Storage in Kubernetes-Clustern bereitgestellt und von Containern sowie Pods „konsumiert“ wird?
Im Gegensatz zu herkömmlichen Storage-Lösungen werden Persistent Volumes in Kubernetes dynamisch selbst verwaltet. Die Aufgabentrennung oder Entkopplung der Speichererstellung und -verwaltung von ihrem Bedarf oder ihrer Anforderung sorgen für größtmögliche Flexibilität. Die Weiche für Anforderungen und Verwaltung erfolgt über einen Persistent Volume Claim. Er ermöglicht es einem Benutzer, deklarativ die Anforderung für persistenten Speicher zu stellen. Die eigentliche Bereitstellung des Speichers – zum Beispiel durch die Erstellung einer Azure Disk – erfolgt meist automatisiert durch Kubernetes selbst.
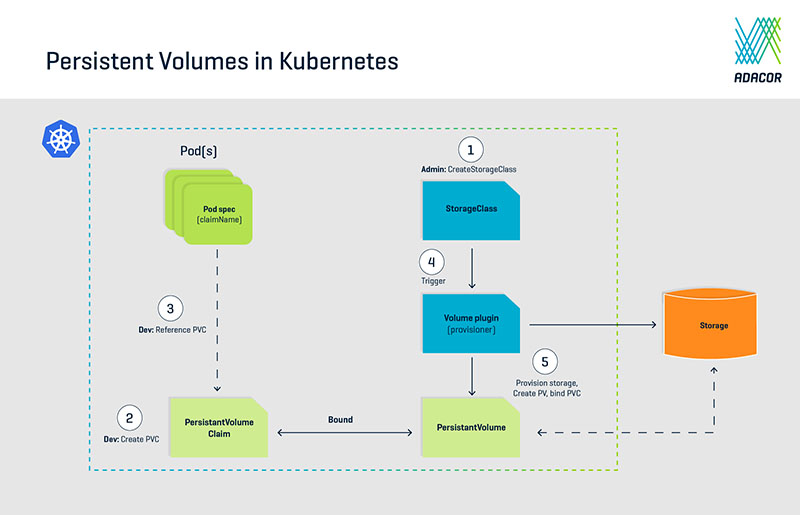
Persistent Volumes in Kubernetes
Konkrete Anwendungsfälle: Development, Testing, Production
Entkopplung und Trennung der Aufgaben führen zu mehr Flexibilität und Portabilität. Werden zum Beispiel verschiedene Umgebungen zur Entwicklung, zum Test und zur Produktion in einem Cluster betrieben, können über den Persistent Volume Claim einmal die Speicheranforderungen für die jeweilige Anwendung deklariert und der Anwendung eine bestimmte Speicher-Klasse zugewiesen werden. Der Persistent Volume Claim verwaltet einen Storage-Pool, aus dem Kubernetes sich – je nach Anwendungsumgebung – mit persistenten Volumes bedienen kann.
Kubernetes Whitepaper für alle IT-Verantwortlichen
Unser Kubernetes Whitepaper ist für alle IT-Verantwortlichen von mittelständischen Unternehmen, die eine zukunftssichere IT-Infrastruktur anstreben. Erfahren Sie im Paper:
- Die Voraussetzungen für den optimalen Einsatz von Kubernetes
- Die wirklich größten Vorteile der Technologie
- Die Unterschiede zwischen dem Einsatz in der Public vs Private Cloud und was für Ihr Unternehmen die richtige Wahl ist
Fazit: Persistent Volumes bieten viele Vorteile
Die Vorteile von Docker und Containern sind unbestritten. Die Instanzen von containerisierten Anwendungen verbrauchen viel weniger Ressourcen als virtuelle Maschinen und ermöglichen größtmögliche Flexibilität. Es gibt aber Daten und Services, zum Beispiel Datenbanken oder Mediendaten, die nach einem beständigen Speichervolumen verlangen. Um einerseits ein Kubernetes-Cluster optimal nutzen zu können und andererseits ein Persistent Volume einzubinden, kann die Verwaltung dieser Anforderung über einen Persistent Volume Claim erfolgen. Sie nutzen den Vorteil, dass Persistent Volumes im Rahmen dieser Lösungen von Kubernetes dynamisch selbst verwaltet werden. Adacor Managed Kubernetes Cluster sind dementsprechend maßgeschneiderte und skalierbare Plattformen für die jeweilige individuelle Kundenanforderung.
Sie möchten mehr Informationen zu Kubernetes?
Dann haben wir weitere spannende Artikel im Blog für Sie zum Lesen.